Análisis de movilidad en México con R y datos abiertos
Introducción
En esta entrada comparto una experiencia práctica de automatización en el acceso y análisis de datos de movilidad humana, tomando como fuente principal el portal Humanitarian Data Exchange (HDX).
Este análisis está orientado al estudio de la distribución de movimiento en México, con énfasis en cómo la automatización puede facilitar procesos repetitivos de obtención y limpieza de datos. El objetivo es hacer uso de herramientas como R para acelerar y escalar proyectos con impacto social, dentro del marco de iniciativas conocidas como Data for Good.
Este tipo de datos puede ser valioso para investigadores, analistas de políticas públicas, periodistas de datos o cualquier persona interesada en entender cómo se mueve la población en situaciones de crisis, como durante una pandemia, migraciones masivas o conflictos humanitarios.
1. Automatización de datos
Automatización del acceso a datos abiertos
Para comenzar, automatizamos el acceso al dataset de “Movement Distribution” en HDX, el cual se actualiza frecuentemente y está compuesto por archivos comprimidos en formato.zip.
Usar un enfoque automatizado para acceder a datos abiertos tiene múltiples beneficios:
- Ahorra tiempo y esfuerzo
- Evita descargas manuales repetidas
- Permite monitorear y detectar nuevas actualizaciones
- Mejora la reproducibilidad del análisis
import unittest
def sumar(a, b):
return a + b#!/bin/bash
# Función simple para probar
saludar() {
echo "Hola, $1"
}
# Pruebas
echo "Test 1: Verificar saludo"
if [ "$(saludar "Mundo")" = "Hola, Mundo" ]; then
echo "Éxito: Test 1 pasó"
else
echo "Fallo: Test 1 no pasó"
fi
echo "Test 2: Verificar existencia de un archivo"
touch prueba.txt
if [ -f "prueba.txt" ]; then
echo "Éxito: Test 2 pasó"
rm prueba.txt
else
echo "Fallo: Test 2 no pasó"
fi
echo "Test 3: Verificar variable vacía"
VAR=""
if [ -z "$VAR" ]; then
echo "Éxito: Test 3 pasó"
else
echo "Fallo: Test 3 no pasó"
fi## Test 1: Verificar saludo
## Éxito: Test 1 pasó
## Test 2: Verificar existencia de un archivo
## Éxito: Test 2 pasó
## Test 3: Verificar variable vacía
## Éxito: Test 3 pasó# 1. AUTOMATIZACIÓN DE DATOS ----
#Primero nos aseguramos cargar las librerías que vamos a utilizar para la extracción de información
pacman::p_load(rvest, httr, stringr, data.table, testthat, dplyr, lubridate, ggplot2, here)
#Automatizar la descarga de datos
# Crear carpeta para descomprimir
dir.create("dB", showWarnings = FALSE)1.1 Extracción de URL’s
import unittest
def sumar(a, b):
return a + b##### 1.1 Extracción de URL's ----
### Navegamos al url de HumData en la sección datasets, encontramos Movement Distribution
url_base <- "https://data.humdata.org"
pagina <- read_html("https://data.humdata.org/dataset/movement-distribution")
# Extraer enlaces y eliminar NAs
# Encontraremos algunos enlaces con NA, así que nos toca remover todos estos espacios vacíos de la lista
enlaces <- pagina %>% html_nodes("a") %>% html_attr("href")
enlaces_zip <- enlaces[str_detect(enlaces, "\\.zip$") & !is.na(enlaces)]1.2 Completamos las URLS relativas
##### 1.2 Completamos las URLS relativas ----
# En este paso vamos a pegar el enlace oiginal o base al nombre del archivo
enlaces_zip_completos <- ifelse(str_starts(enlaces_zip, "http"),
enlaces_zip,
paste0(url_base, enlaces_zip))
#Eliminamos el objeto página, no lo necesitamos mas
rm(pagina)1.3 Limpieza de enlaces y preprocesamiento de descargas
##### 1.3 Limpieza de enlaces y preprocesamiento de descargas ----
#LImpiamos el vector para eliminar .zip.zip
limpiar_enlaces_zip <- basename(enlaces_zip)
enlaces_zip <- sub("(\\.zip)+$", ".zip", limpiar_enlaces_zip)
# Listar archivos ZIP en la carpeta 'dB'
archivos_zip <- list.files("dB", pattern = "\\.zip$", full.names = TRUE)1.4 Revisamos aquellos que ya tenemos en histórico
##### 1.4 Revisamos aquellos que ya tenemos en histórico ----
#Vamos a comparar los enlaces que tenemos contra los que no tenemos
missing_enlaces <- setdiff(basename(archivos_zip), enlaces_zip)
#Verificamos si tenemos algún archivo que no hemos descargado aún
indice_missing <- which(enlaces_zip %in% missing_enlaces)
#Actuaizamos el vector con la lista de elementos que nos hacen falta para descargar
enlaces_zip_completos <- enlaces_zip_completos[indice_missing]1.5 Descarga condicional
##### 1.5 (Condicional) Si nos falta algún archivo o hay actualización, descargamos ----
if(length(enlaces_zip_completos) >0){
# Inciamos la descarga masiva de archivos .zip
for (enlace in enlaces_zip_completos[1:length(enlaces_zip_completos)]) {
nombre_archivo <- basename(enlace)
cat("Descargando:", nombre_archivo, "\n")
GET(enlace, write_disk(file.path("dB", nombre_archivo), overwrite = TRUE)) #Descomentar
}
}else{
print("No hay datos nuevos que mostrar")
}## [1] "No hay datos nuevos que mostrar"1.6 Renombrar archivos y limpieza final de las descargas
##### 1.6 Renombrar archivos y limpieza final de las descargas----
#Una vez que tenemos la descargas listas verificamos el directorio y reconocemos los archivos .zip
# Listamos archivos descargados en /dB
archivos <- list.files("dB", pattern = "\\.zip", full.names = TRUE)
# Nuevamente volvemos a revisar la procedencia de los archivos y
# renombramos aquellos con múltiples extensiones .zip a una sola extensión .zip
for (archivo in archivos) {
nombre_correcto <- sub("(\\.zip)+$", ".zip", archivo) # reemplaza múltiples ".zip" por uno solo
file.rename(archivo, nombre_correcto) #Descomentar
}
#En este punto ya tenemos nuestros datos actualizados con frecuencia mensual2. Extracción y descompresión de archivos
Una vez descargados, descomprimimos los archivos .zip y buscamos archivos.csvdentro de ellos. No todos los países nos interesan: en este proyecto nos enfocamos exclusivamente en México.
# 2. EXTRACCIÓN Y DESCOMPRESIÓN DE ARCHIVOS ----
# Listar archivos ZIP en la carpeta 'dB'
archivos_zip <- list.files("dB", pattern = "\\.zip$", full.names = TRUE)
missing_zip <- archivos_zip[indice_missing]
missing_csv <- c()
if(length(missing_zip)>0){
for (zipfile in missing_zip) {
print(zipfile)
cat("Descomprimiendo:", zipfile, "\n")
unzip(zipfile, exdir = "dB") # Descomentar
# Listar contenido del zip
contenido <- unzip(zipfile, list = TRUE)
nombres_csv <- contenido$Name[grep("\\.csv$", contenido$Name)]
# Agregar al vector global
missing_csv <- c(missing_csv, nombres_csv)
rm(contenido, pagina)
}
}else{
print("Nada que descomprimir")
}## [1] "Nada que descomprimir"3. Carga y filtrado de datos por país
# 3. CARGA Y FILTRADO DE DATOS POR PAIS ----
# Leer todos los archivos CSV extraídos en un solo data.table
archivos_csv <- list.files("dB", pattern = "\\.csv$")
archivos_csv <- setdiff(archivos_csv, "datos_mexico_completos.csv")
fechas <- sub(".*_(\\d{4}-\\d{2}-\\d{2})\\.csv$", "\\1", archivos_csv)if(!file.exists("dB/datos_mexico_completos.csv")){
dt_mex <- NULL
# Procesar cada archivo (sólo necesitamos MEX)
for (archivo in archivos_csv) {
cat("Procesando:", archivo, "\n")
tmp <- fread(paste0("dB/",archivo)
)[country == "MEX"][, ':=' (gadm_name = ifelse(gadm_name == "NA", NA, gadm_name),
ds = as.Date(ds),
distance_category_ping_fraction = round(distance_category_ping_fraction, 5)
)][,nameFile := archivo]
dt_mex <- rbind(dt_mex, unique(tmp))
rm(tmp)
}
fwrite(dt_mex, "dB/datos_mexico_completos.csv")
}else{
dt_mex <- unique(fread("dB/datos_mexico_completos.csv",
colClasses = list(
character = c("gadm_id", "gadm_name", "country", "home_to_ping_distance_category", "nameFile"),
Date = "ds",
integer = "polygon_level",
numeric = "distance_category_ping_fraction"
)))
if(!is.null(missing_csv)){
dt_mex_2 <- NULL
for(file in (missing_csv)){
print(file)
tmp <- unique(fread(paste0("dB/",file)
)[country == "MEX"][, ':=' (gadm_name = ifelse(gadm_name == "NA", NA, gadm_name),
ds = as.Date(ds),
distance_category_ping_fraction = round(distance_category_ping_fraction, 5)
)][,nameFile := file])
dt_mex_2 <- rbind(dt_mex_2, tmp)
rm(tmp)
invisible(gc())
}
MEX_Data <- unique(rbind(dt_mex, unique(dt_mex_2)))
rm(dt_mex, dt_mex_2)
fwrite(MEX_Data, "dB/datos_mexico_completos.csv")
}else{
MEX_Data <- copy(dt_mex)
rm(dt_mex)
invisible(gc())
}
}4. Enriquecimiento con variables temporales
MEX_Data[,home_to_ping_distance_category] %>% unique()## [1] "(0, 10)" "100+" "0" "[10, 100)"factor_dias_espanol <- c("Lunes", "Martes", "Miércoles", "Jueves", "Viernes", "Sábado", "Domingo")
factor_ping_cat <- c("0", "(0, 10)", "[10, 100)", "100+" )
MEX_Data[, c("pais", "Entidad", "Municipio") := tstrsplit(gadm_id, "[._]", keep = 1:3)]
MEX_Data[Entidad %in% c(9) ][,.(Fecha =as.Date(ds),
Pais = country,
Entidad,
Municipio, gadm_name,
home_to_ping_distance_category,
distance_category_ping_fraction = round(distance_category_ping_fraction,3))] -> dt_cdmx
# Agregar columnas derivadas de la fecha con días en español
dt_cdmx[, `:=`(
Año = year(Fecha),
Mes = month(Fecha),
Día = mday(Fecha),
DíaSemana = factor_dias_espanol[wday(x=Fecha, week_start = 1)],
NSemana = isoweek(Fecha),
Trimestre = quarter(Fecha)
)][, DíaSemana :=factor(DíaSemana, levels =factor_dias_espanol)
][, home_to_ping_distance_category := factor(home_to_ping_distance_category, levels = factor_ping_cat)] -> dt_cdmx
dt_cdmx[,gadm_name := ifelse(gadm_name=="Magdalena Contreras", "La Magdalena Contreras", gadm_name) ]5. Visualización de movilidad en la Ciudad de México
dt_cdmx$DíaSemana %>% unique()## [1] Jueves Viernes Sábado Domingo Lunes Martes Miércoles
## Levels: Lunes Martes Miércoles Jueves Viernes Sábado Domingodt_cdmx[Fecha >= "2024-01-01" & Fecha < "2025-01-01" & gadm_name == "Miguel Hidalgo"
][,.(Fecha, Entidad, Municipio, gadm_name,
home_to_ping_distance_category, distance_category_ping_fraction,
Año, Mes, Día, DíaSemana, NSemana)] -> ggdata
ggdata## Fecha Entidad Municipio gadm_name
## <Date> <char> <char> <char>
## 1: 2024-01-01 9 11 Miguel Hidalgo
## 2: 2024-01-01 9 11 Miguel Hidalgo
## 3: 2024-01-01 9 11 Miguel Hidalgo
## 4: 2024-01-01 9 11 Miguel Hidalgo
## 5: 2024-01-02 9 11 Miguel Hidalgo
## ---
## 1460: 2024-12-30 9 11 Miguel Hidalgo
## 1461: 2024-12-31 9 11 Miguel Hidalgo
## 1462: 2024-12-31 9 11 Miguel Hidalgo
## 1463: 2024-12-31 9 11 Miguel Hidalgo
## 1464: 2024-12-31 9 11 Miguel Hidalgo
## home_to_ping_distance_category distance_category_ping_fraction Año
## <fctr> <num> <num>
## 1: 0 0.400 2024
## 2: [10, 100) 0.077 2024
## 3: (0, 10) 0.505 2024
## 4: 100+ 0.018 2024
## 5: [10, 100) 0.060 2024
## ---
## 1460: 100+ 0.009 2024
## 1461: 0 0.352 2024
## 1462: [10, 100) 0.082 2024
## 1463: 100+ 0.006 2024
## 1464: (0, 10) 0.560 2024
## Mes Día DíaSemana NSemana
## <num> <int> <fctr> <num>
## 1: 1 1 Lunes 1
## 2: 1 1 Lunes 1
## 3: 1 1 Lunes 1
## 4: 1 1 Lunes 1
## 5: 1 2 Martes 1
## ---
## 1460: 12 30 Lunes 1
## 1461: 12 31 Martes 1
## 1462: 12 31 Martes 1
## 1463: 12 31 Martes 1
## 1464: 12 31 Martes 1dt_cdmx[Fecha >= "2024-01-01" & Fecha < "2025-01-01" & Entidad==9
][,.(avg_fraction = mean(distance_category_ping_fraction, na.rm = TRUE)),
keyby = .(gadm_name, home_to_ping_distance_category)][order(home_to_ping_distance_category, gadm_name)]## gadm_name home_to_ping_distance_category avg_fraction
## <char> <fctr> <num>
## 1: Alvaro Obregón 0 0.361218579
## 2: Azcapotzalco 0 0.347286885
## 3: Benito Juárez 0 0.367989071
## 4: Coyoacán 0 0.369229508
## 5: Cuajimalpa de Morelos 0 0.369472678
## 6: Cuauhtémoc 0 0.358374317
## 7: Gustavo A. Madero 0 0.361989071
## 8: Iztacalco 0 0.373464481
## 9: Iztapalapa 0 0.375986339
## 10: La Magdalena Contreras 0 0.364923497
## 11: Miguel Hidalgo 0 0.354155738
## 12: Milpa Alta 0 0.380778689
## 13: Tlalpan 0 0.366155738
## 14: Tláhuac 0 0.384942623
## 15: Venustiano Carranza 0 0.372579235
## 16: Xochimilco 0 0.370013661
## 17: Alvaro Obregón (0, 10) 0.563420765
## 18: Azcapotzalco (0, 10) 0.567696721
## 19: Benito Juárez (0, 10) 0.568106557
## 20: Coyoacán (0, 10) 0.549896175
## 21: Cuajimalpa de Morelos (0, 10) 0.562142077
## 22: Cuauhtémoc (0, 10) 0.566650273
## 23: Gustavo A. Madero (0, 10) 0.552521858
## 24: Iztacalco (0, 10) 0.545366120
## 25: Iztapalapa (0, 10) 0.535000000
## 26: La Magdalena Contreras (0, 10) 0.552628415
## 27: Miguel Hidalgo (0, 10) 0.573674863
## 28: Milpa Alta (0, 10) 0.526571038
## 29: Tlalpan (0, 10) 0.541530055
## 30: Tláhuac (0, 10) 0.526256831
## 31: Venustiano Carranza (0, 10) 0.543336066
## 32: Xochimilco (0, 10) 0.540535519
## 33: Alvaro Obregón [10, 100) 0.071327869
## 34: Azcapotzalco [10, 100) 0.075609290
## 35: Benito Juárez [10, 100) 0.059609290
## 36: Coyoacán [10, 100) 0.077939891
## 37: Cuajimalpa de Morelos [10, 100) 0.065508197
## 38: Cuauhtémoc [10, 100) 0.066833333
## 39: Gustavo A. Madero [10, 100) 0.076642077
## 40: Iztacalco [10, 100) 0.078054645
## 41: Iztapalapa [10, 100) 0.086907104
## 42: La Magdalena Contreras [10, 100) 0.080245902
## 43: Miguel Hidalgo [10, 100) 0.065245902
## 44: Milpa Alta [10, 100) 0.091043716
## 45: Tlalpan [10, 100) 0.090133880
## 46: Tláhuac [10, 100) 0.087038251
## 47: Venustiano Carranza [10, 100) 0.081557377
## 48: Xochimilco [10, 100) 0.088021858
## 49: Alvaro Obregón 100+ 0.004049180
## 50: Azcapotzalco 100+ 0.009349727
## 51: Benito Juárez 100+ 0.004314208
## 52: Coyoacán 100+ 0.002975410
## 53: Cuajimalpa de Morelos 100+ 0.002926230
## 54: Cuauhtémoc 100+ 0.008120219
## 55: Gustavo A. Madero 100+ 0.008887978
## 56: Iztacalco 100+ 0.003084699
## 57: Iztapalapa 100+ 0.002060109
## 58: La Magdalena Contreras 100+ 0.002166667
## 59: Miguel Hidalgo 100+ 0.006896175
## 60: Milpa Alta 100+ 0.001581967
## 61: Tlalpan 100+ 0.002174863
## 62: Tláhuac 100+ 0.001726776
## 63: Venustiano Carranza 100+ 0.002568306
## 64: Xochimilco 100+ 0.001385246
## gadm_name home_to_ping_distance_category avg_fractionggdata %>%
ggplot(., aes(x = Fecha, y = distance_category_ping_fraction,
fill = home_to_ping_distance_category)) +
geom_bar(stat = "identity", position = "fill") + # Barras apiladas con las proporciones
labs(
title = "Proporción de categorías de distancia en Miguel Hidalgo",
x = "Fecha",
y = "Proporción (distance_category_ping_fraction)",
fill = "Categoría de distancia"
) +
scale_fill_brewer(palette = "Set2") -> grafico_Apiladas_CDMXVisualización histórica
A continuación, un gráfico que representa la distribución acumulada:
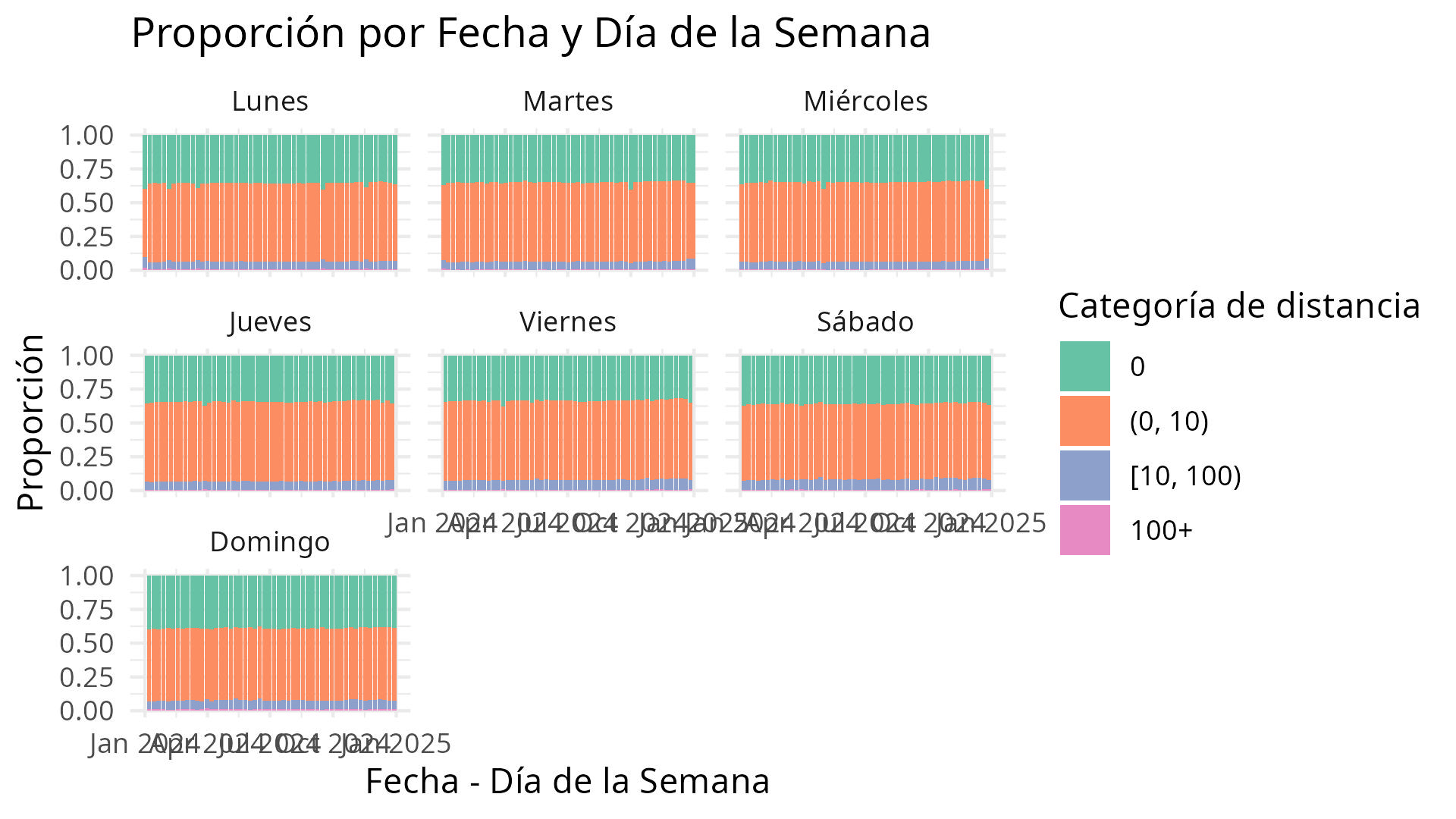
Este gráfico permite visualizar tendencias de movilidad.
ggdata %>%
ggplot(., aes(x = Fecha, y = distance_category_ping_fraction,
fill = home_to_ping_distance_category)) +
geom_bar(stat = "identity", position = "fill") +
facet_wrap(~DíaSemana) +
labs(
title = "Proporción por Fecha y Día de la Semana",
x = "Fecha - Día de la Semana",
y = "Proporción",
fill = "Categoría de distancia"
) +
theme_minimal() +
scale_fill_brewer(palette = "Set2") -> grafico_Barras_CDMXruta_salida <- "/home/alan/Documents/R Experiments/dataforgood-movementdist/DataOut/Download_Load/jpeg"
ggsave(filename = file.path(ruta_salida, "grafico_Barras_CDMX.jpeg"),
plot = grafico_Barras_CDMX,
width = 1920, height = 1080, units = "px", dpi = 300)Visualización semanal
A continuación, un gráfico que representa la distribución acumulada por día de la semana:
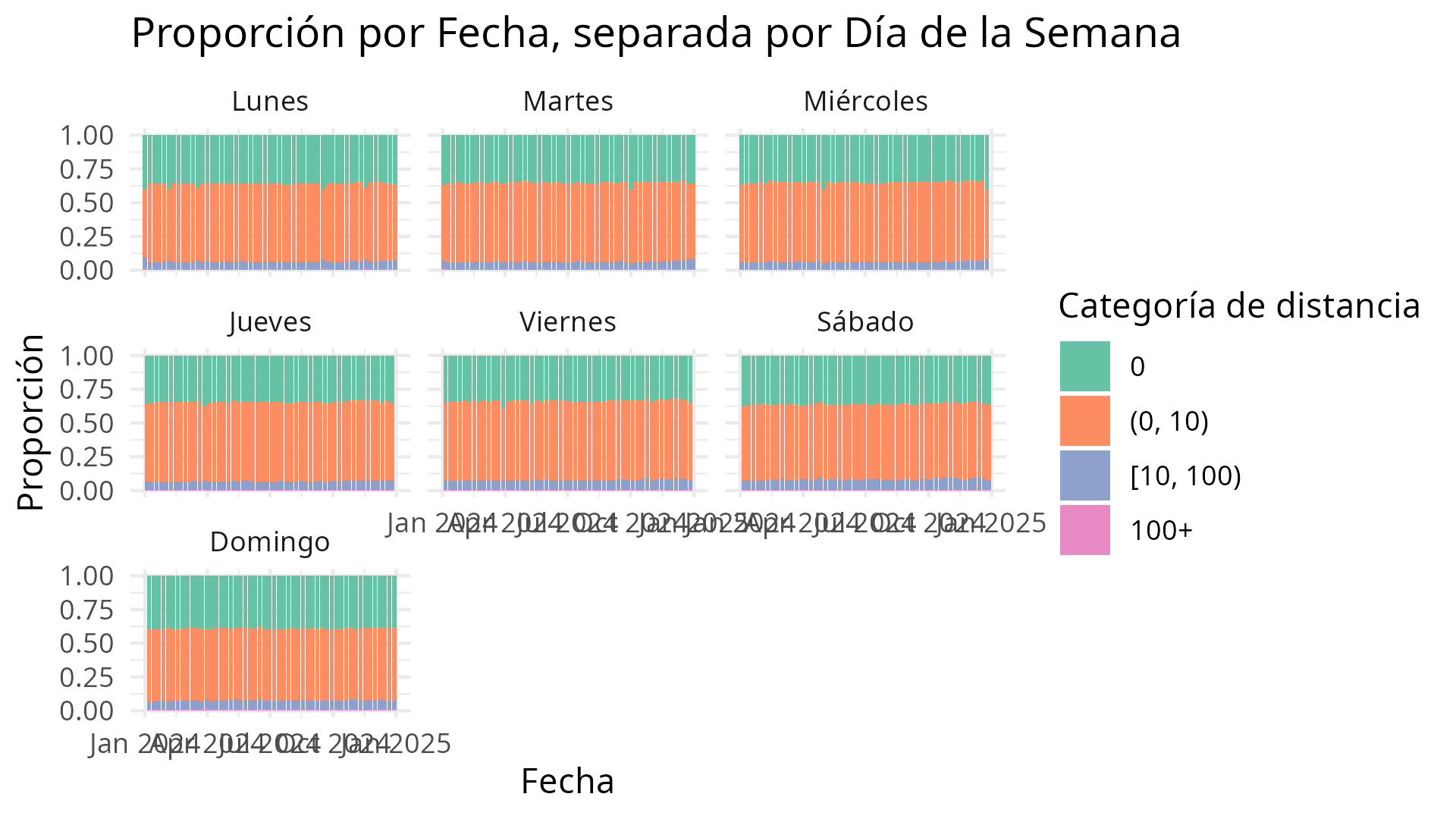
Este gráfico permite visualizar tendencias semanales de movilidad.
ggplot(ggdata, aes(x = Fecha, y = distance_category_ping_fraction,
fill = home_to_ping_distance_category)) +
geom_bar(stat = "identity") +
facet_wrap(~ DíaSemana) +
labs(
title = "Proporción por Fecha, separada por Día de la Semana",
x = "Fecha",
y = "Proporción",
fill = "Categoría de distancia"
) +
theme_minimal() +
scale_fill_brewer(palette = "Set2") -> grafico_Barras_Dias_CDMXggsave(filename = file.path(ruta_salida, "grafico_Barras_Dias_CDMX.jpeg"),
plot = grafico_Barras_Dias_CDMX,
width = 1920, height = 1080, units = "px", dpi = 300)Conclusiones
Este proyecto demuestra cómo las herramientas de automatización con R pueden facilitar el acceso, limpieza, procesamiento y visualización de datos abiertos a gran escala.
El tiempo ahorrado puede invertirse en analizar mejor los datos, comunicar los hallazgos y generar impacto en iniciativas sociales. En este caso, exploramos un ejemplo dedata for good, aplicando análisis de datos al estudio de movilidad humana en contextos de crisis.
Si te interesa este tipo de proyectos o deseas colaborar, puedes encontrar el código en GitHub y explorar más visualizaciones en este sitio.
Respuestas